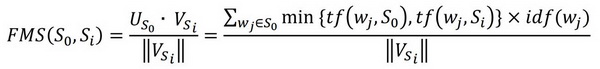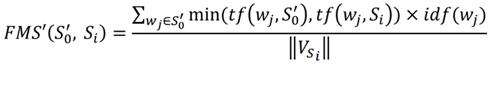The respected Comrade
"Great efforts should be made in the field of cutting-edge science and technology to develop technologies with a world-class competitive edge."
Translation Memory (TM) technique is a key functionality being widely used in the field of Computer Assisted Translation (CAT). Of course, the choice of TM matching method is important for improving the effectivity of TM system. But what is no less important than any TM matching method is to use a reasonable size TM. We propose a method to achieve high-speed retrieval from a large translation memory by means of similarity evaluation based on vector model, and present the experimental result.
When retrieving from a large TM, it is common and reasonable to use the two-stage approach in which the TM system filters candidates likely to be related to the input sentence for TM matching and then finds the most similar segments by fine-grained matching. The filtering is referred to the primary retrieval and the fine-grained finding is referred to the secondary retrieval.
For the vector representation of the input sentence, S0 and the source segment, Si, in the TM, we suggest using TF-IDF weight of the words, which is commonly used feature for IR.
Given two vectors, VSi for Si and US0 for S0, the similarity score of the input sentence S0 and the source segment Si can be defined as follows:
where tf (wj, S0) and tf (wj, Si) are the frequencies of the term wj in the input sentence S0 and the source segment Si, respectively and idf (wj) is the inversed document frequency of the term wj.
Our solution to evaluate semantic similarity taking into account the synonym knowledge in the primary retrieval of TM, is to change the input sentence S0 into a pseudo sentence S'0 which includes all the words of S0 and also their synonym words, and then calculate the similarity score of the pseudo sentence S'0 and the source segments of TM.
WordNet is a useful knowledge database for finding synonym for English. According to our analysis of WordNet 3.0, it has a total of 117,659 senses with 147,306 words related to each other. Among those words, there are 49,754 words which do not have any synonyms at all. Using our own principles for synonym selection, we selected 36,185 senses with 90,258 words related to each other to build an English synonym dictionary for TM retrieval.
Through our experiment using Lucene, an open source information retrieval search engine, we concluded that it is possible to achieve real-time retrieval speed of about tens of microseconds even for a large translation memory with 5 million segment pairs. When there is a translation unit whose source segment is the same as the input sentence, the translation unit ranks at the first place in the primary retrieval result of TM. The automatic checking result of the source segments included in the TM shows that Lucene is an effective means for exact match, as well as fuzzy matching.
Our result was published with the title of "Translation Memory Retrieval Using Lucene"(https://doi.org/10.26615/978-954-452-072-4_078) in the Proceedings of Recent Advances in Natural Language Processing-2021.